Training AI to play Super Smash Bros. Melee
I trained a 20 million parameter Transformer on 3 billion frames of professional Fox player replays.
It wins 95% of the time against the in-game level 9 CPU, and only cost me about $5 to train on two 3090s in 5 hours.1
Here it is playing as Fox (on the left):
It’s not set up yet to play humans today, but I wanted to share my progress because having a model that works at all is a big milestone.
So far, I’ve spent over 300 hours setting up infrastructure, munging data, dealing with emulator bugs, thinking about the right feature representations, and running experiments. My goal is to eventually make a model strong enough to beat the best pro players, with human-level reaction time and running in real-time on consumer hardware.
Today, I’ll go into detail on my data processing, supervised learning, and evaluation setup. In future blog posts, I’ll focus more on reinforcement learning, inference optimizations, and making it playable for humans!
For more videos of the model playing, skip to Footage. Code is here.
This post assumes technical knowledge of deep learning from the reader.
Table of contents
Why?
Because it’s cool.
I believe the best projects speak to you on multiple levels, and this one was no different.
- Melee is sick
- I love the janky gameplay, grassroots community, personalities, and tournament storylines. I’ve followed the competitive scene for over 10 years and never get sick of the game.
- This was important for not getting tired of debugging emulator issues or analyzing endless data & replays.
- The timing felt right
- In the post-covid Slippi era, all the ingredients needed for imitation learning were in place. Large dumps of anonymized human replays from around the world are available in a portable format. Recent improvements to the emulator made faster-than-real-time rollouts possible, thanks to hard work from Fizzi and Vlad.
- I saw a chance to give something unique to the community
- The fighting game community never had its Deep Blue moment. AlphaStar and OpenAI Five made a big splash in 2018-2019 by conquering my favorite RTS games (and inspired me to pursue ML as a career), but a disappointing aspect was how these foundation labs moved on and never open-sourced code or weights.
- I plan to open-source my models and, hopefully, a training tool that can push Melee players to deeper levels of understanding in the game.2
- I like training models
- I just enjoy designing training runs and building up my ML intuition. Watching loss curves go down is addictive, and it’s all the more meaningful because you know it means something is cooking—a bit like pulling a lottery ticket after you’ve “paid” with thinking of an idea or configuration and coded it up. And the reward is seeing gameplay improvement magically emerge from a tiny set of weights!
- Generally, it seems helpful to have this kind of enjoyable inner loop in large projects to keep you going when overall progress stalls.
- It’s relevant to my career
- I found that I used almost everything I learned in ML and software engineering on this project—writing maintainable code; running experiments; distributed training with good logging; designing evals; inference optimization.
- Building this project also gave me a testbed for future research ideas.
- Usually, when coding for a day job, you are not the primary consumer of the code you write. It was fun and freeing to write code for myself, and I also got to really dogfood and internalize learnings from dealing with my past self’s mistakes.
What is Melee?
Most people I’ve met have heard of Super Smash Bros., but not everyone knows that there’s a vibrant esports scene. If you’re unfamiliar, I find it’s easiest to understand the appeal of Melee by watching a game.
Very briefly, the competitive ruleset has the following constraints:
- there are 6 tournament legal stages
- you can pick any character
- no items
- you have 4 lives (“stocks”) each, 8 minute time limit
- your goal is to hit each other off the stage: last person standing wins
For a really long deep dive, you can watch The Smash Brothers documentary, which is how I was turned on to the game in college.
Previous Work
The citable literature on Melee is outdated. Since this is a blog post, I’ll describe the landscape as I understand it.
Past attempts to train a model by Vlad Firoiu (Phillip) and Bryan Chen (Project Nabla) achieved impressive results using imitation learning + reinforcement learning. Phillip is state of the art—as far as I know, it goes head-to-head with some of the strongest players, but I have a feeling things can be pushed further.
For one, previous projects used LSTM architectures and trained character-specific models. I strongly believe a single Transformer trained on all character replays would out-perform and be more efficient to train. General concepts like spacing and positioning are fundamentally the same across all matchups, and the bitter lesson certainly applies to Melee.
I was also eager to play around with more feature representations, hyperparameter sweeps, and offline RL algorithms before moving on to self-play RL. My hunch is that a better, more expressive base model translates to improved priors, more coverage of states, and thus, better downstream performance.
Eventually, I’m interested in AlphaStar-style population-based RL. This cool paper by Czarnecki et al., 2020 suggests that learning Nash equilibriums for two-player zero-sum games sometimes requires population learning to get out of cycles of suboptimal strategies.
Methodology
Now that we’ve convinced ourselves we should invest our free time training a model to play a 25 year old children’s party game, how do we go about it?
We want the bot to be fun and fair to play against, and we want players around the world to be able to run it locally.
Our goal, then, is to train the best performing model possible, subject to the following constraints:
- Single model for all 1v1 stages & matchups
- Human-like play style
- Human-level reaction time
- Runs at real-time (60 fps) on consumer hardware
From the Slippi discord server, it turns out we have an emulator, a large dump of ~100k anonymized human replays in a .slp file format, and a python API called libmelee for running the emulator as well as reading recorded game states and controller inputs from .slp files. We can also get access to some pro players’ replays if we ask nicely.
For the first stage of the project, we’ll approach the problem as a supervised learning (behavior cloning) task. This should be a strong baseline because we have a lot of expert demonstrations. The model will hopefully learn to copy its distribution, giving us human-like play style and reaction times by default.
In behavior cloning, low training or validation loss doesn’t guarantee the model will perform well in the real environment. The best way to quantitatively measure training performance is to define some closed-loop evaluation metrics—e.g. having the model play against the in-game CPU and measuring damage dealt or stock win rate—so we’ll have to also build an evaluation harness with the emulator.

With the high level approach defined, let’s dive in.
Data
I began with 100k replays, but by the end of the project, I had over 1 million. Here’s how I processed 4TB of .slp files and compressed them to 200GB.3
I started by looking at the replay data, visualizing it, looking at summary statistics, and noting any outliers or noisy/missing fields. Each episode (episode == replay) is generally sparse and autocorrelated. I filtered replays for 1v1 matches and discarded those that had encoding errors, were incomplete, were below a certain duration, or registered no damage.
.slp files have to be read by libmelee and don’t support arbitrary seeks or slicing across frames, so I saved each replay as a 2D array where each column represents a game state feature, each row represents one frame.
| frame | stage | p1_char | p1_stock | p1_action | p1_jumps_left | p1_facing | p1_position_x | p1_position_y | p1_invulnerable | p1_main_stick_x | p1_main_stick_y | p1_button_a | … | p2_char | p2_stock | p2_action | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | FOX | 4 | ON_HALO_DESCENT | 1 | 1 | -41.25 | 21.00 | 1 | 0.0 | 0.0 | 0 | … | MARTH | 4 | ON_HALO_DESCENT | … |
| 1 | 3 | FOX | 4 | ON_HALO_WAIT | 0 | 1 | -41.25 | 21.00 | 1 | 0.0 | 0.0 | 0 | … | MARTH | 4 | ON_HALO_WAIT | … |
| 2 | 3 | FOX | 4 | FALLING | 0 | 1 | -41.25 | 21.08 | 0 | 0.0 | 0.3 | 0 | … | MARTH | 4 | FALLING | … |
| 3 | 3 | FOX | 4 | FALLING | 0 | 1 | -41.25 | 21.13 | 0 | 0.0 | 0.3 | 1 | … | MARTH | 4 | FALLING | … |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 8370 | 3 | FOX | 1 | DAMAGE_AIR_3 | 0 | 0 | 126.21 | -135.46 | 0 | 0.9875 | -0.7 | 0 | … | MARTH | 2 | DAIR | … |
| 8371 | 3 | FOX | 0 | DEAD_DOWN | 0 | 0 | 129.58 | -146.82 | 0 | 1.0 | -0.7 | 0 | … | MARTH | 2 | DAIR | … |
Data format and loader
However, an unexpected sticking point was deciding on the right storage format for the full dataset.
In Melee, game states beyond the past 5 seconds rarely matter for the next action in a given frame. This is good because it means we can keep the sequences short and memory usage low instead of training on entire replays (important for quadratic attention).
For training, we want to perform two random samplings: first, selecting from replays, and second, selecting rows within a chosen replay. But, we can’t just concatenate all rows into a single massive 2D array. For one, that’d be 10 billion rows. Also, naively grabbing seq_len contiguous rows towards the end of one episode would include rows from the next episode.
The dataset is just big enough to not fit in memory on a big machine, so we need file shards on disk for efficient shuffling and sampling. I wasted a lot of time at the beginning trying to get PyArrow and Parquet working, misled by ChatGPT’s sweet guile. Vlad had also used it in his project, but columnar storage is pretty bad for fast, random row accesses. You can’t retrieve data from disk by row index without decompressing and deserializing the entire column for the entire dataset, unless you maintain some mapping of indices to row groups or file partitions. Consequently, it’s also unfriendly for distributed training, where multiple GPU processes might have multiple data workers, each needing to redundantly deserialize huge chunks of the dataset.
I also experimented with memory-mapping .npy. This had the disadvantage of being restricted only to numpy-supported data types, being disk space inefficient, and still required careful coordination of concurrent workers to avoid effectively reading the entire dataset into memory simultaneously.
Searching online yielded only other unsatisfactory options like CSV, pickle or torch tensor (.pkl/.pt) files, TFRecord, HDF5, and LMDB. It seemed ridiculous that I couldn’t find a better data format and loader for my use case. I even started rolling my own by serializing the entire dataset as a torch.tensor in memory and sharing it across DDP processes using ForkingPickler.
Eventually, I came across Mosaic Streaming, which I’ve since used for LLM training. (Serious question: what were people using before this for sequence learning? Perplexity and o1 pro Deep Research could not think of this for my use case.)
Happily, StreamingDataset is a drop-in replacement for PyTorch Dataset, but also supports automatic compression, streaming directly from S3, mixing datasets, and deterministic resumption. I treated each episode as a separate record and randomly sampled a sequence within an episode in Dataset.__getitem__. This slightly over-samples frames from shorter episodes, which is negligible given how few epochs I’m likely to train on a large dataset.
As others have similarly concluded, I experimented between algorithms and found brotli to have about 20% better compression ratios that zstd in my use case, but I chose zstd for the faster decompression speeds for training. Because of the data sparsity, zstd already achieved >20x compression ratios, which I was happy with.
1 │ data/ranked/
2 │ ├── [4.0K] diamond
3 │ │ ├── [4.0K] test
4 │ │ │ ├── [ 40K] index.json
5 │ │ │ ├── [ 81M] shard.00000.mds.zstd
6 │ │ │ ├── [ 80M] shard.00001.mds.zstd
7 │ │ │ ├── [ 81M] shard.00002.mds.zstd
8 │ │ ...
11 │ │ ├── [ 44K] train
12 │ │ │ ├── [3.6M] index.json
13 │ │ │ ├── [2.0G] shard.00000.mds
14 │ │ │ ├── [ 81M] shard.00000.mds.zstd
15 │ │ │ ├── [2.0G] shard.00001.mds
16 │ │ │ ├── [ 80M] shard.00001.mds.zstd
17 │ │ │ ├── [2.0G] shard.00002.mds
18 │ │ │ ├── [ 81M] shard.00002.mds.zstd
19 │ │ │ ├── [2.0G] shard.00003.mds
20 │ │ ...
1144 │ ├── [4.0K] master
1145 │ │ ├── [ 16K] train
1146 │ │ │ ├── [1.9M] index.json
1147 │ │ │ ├── [2.0G] shard.00000.mds
1148 │ │ │ ├── [2.0G] shard.00001.mds
1149 │ │ │ ├── [2.0G] shard.00002.mds
1150 │ │ │ ├── [2.0G] shard.00003.mdsPreprocessing
Normalizing input features was straightforward, but the target features required some care.
Buttons
The GameCube controller has both digital and analog inputs that interact in precise ways.4 There are 6 buttons (A, B, X, Y, Z, D-Pad right), two analog sticks (“main”/control stick and c-stick), and two shoulders (L/R) that matter for gameplay.

Players often hold multiple buttons on the same frame, but the game engine only notices button presses and releases. For instance, in-game button presses on the left are recorded in .slp for all the frames the button is held down.
frame | in-game
1 L down
2 X down
3
4 X up
5
6
7 L up A down
8 frame | in .slp
1 L
2 L X
3 L X
4 L X
5 L
6 L
7 L A
8 Aframe | preprocessed
1 L
2 X
3 X
4 X
5
6
7 A
8 AI preprocessed this to reduce the problem to single-label instead of multi-label classification (to avoid modeling joint probabilities for 6 independent buttons per frame5). I also combined X/Y and L/R buttons. In hindsight, I’m not sure these decisions were correct at the margins but it was hard to evaluate until the rest of the project was complete.
Analog sticks
Dolphin sends analog stick x, y values as int8, and Melee internally clips those to [-80, 80]. There’s a cross-shaped dead zone at [-22, 22] for ergonomic reasons, where values are clamped to the nearest axis or to the origin.
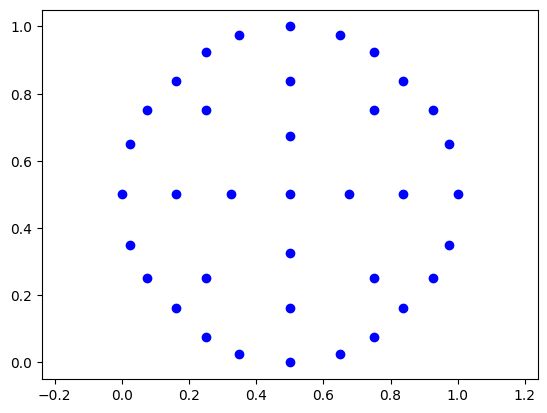
Using MSE to regress on continuous controls can be a training bottleneck due to vanishing gradients. We could learn to classify 117 positions for each axis, but most would go unused. I decided to cluster joint x, y positions and use cross-entropy loss for everything to avoid weighing losses of different scales.
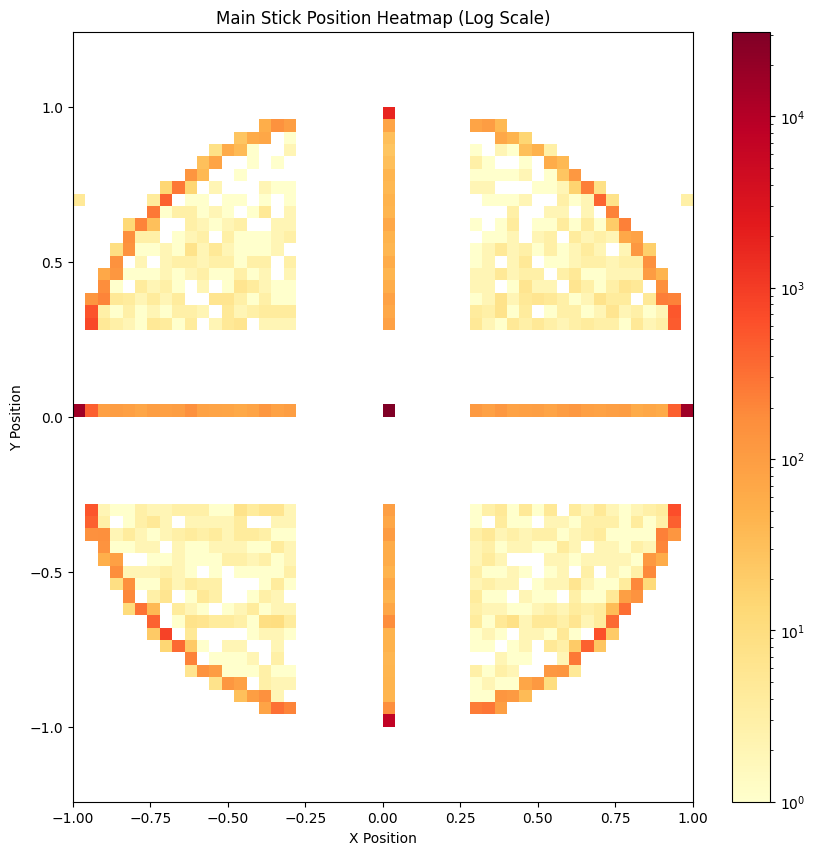
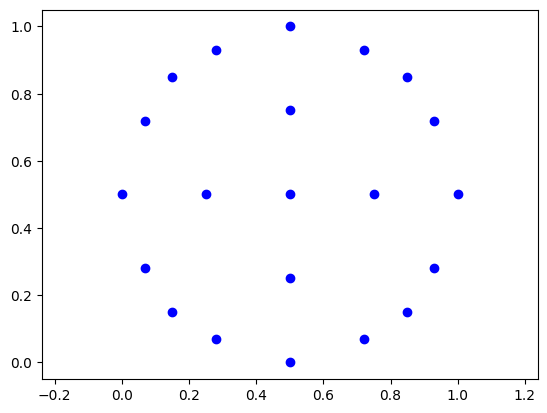
100k x, y positions randomly sampled from 100M frames; 21 relatively evenly spaced cluster centers found using k-means++
A target feature with less class imbalance seemed more tractable for the model to learn, even if it introduced some divergence in closed loop.
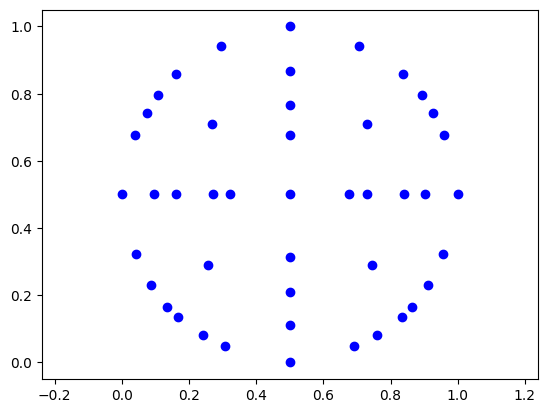
In later experiments, I tried finer-grained discretizations by adding more clusters as well as hand-picking points using Altimor’s StickMap to encourage more expressivity. I haven’t yet tried predicting stick x, y positions independently, but if you’re curious to see the results, skip to Experiments.
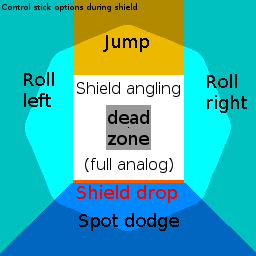


certain moves like shield drops and ledge dashes require precise stick positions
Limitations
Due to limits in the API, the following were not encoded for the AI to observe:
Training
For training, we use next-token prediction on a decoder-only Transformer—the same way LLMs are trained. Given N frames of game state, predict the controller inputs for frame N+1, simultaneously for all N < sequence length.

By far the most important thing I did was to overfit on a single synthetic example, and debug until I was sure that my training and closed loop eval data distributions perfectly matched.
In this case, I generated a single episode in emulator using a hand-designed multishine.py script, saved it as a dataset, preprocessed it, and repeatedly trained a model until it achieved epsilon training loss and perfectly reproduced the script’s behavior in emulator. This “closed the loop” and helped me find all sorts of bugs that I had in my preprocessing and eval code, and eventually, larger flaws in model architecture. A highly regular demonstration can be reasoned about in closed loop without divergence; therefore model inputs & outputs can be saved off and compared frame-by-frame with the training example. This is basically what Karpathy recommends in Recipe for Training NNs. If I had zeroed in on this idea from the beginning, I would have saved a lot of time.
Once I had ironed out all the inconsistencies between train and eval, my model still was not fitting multishine. I concluded the model either did not have enough information about the environment, enough expressive power, or both. I found that both adding controller inputs from previous frames (teacher forcing) and changing the output heads to be MLPs instead of shallow linear layers were crucial. Finally, decoding output heads auto-regressively helped the model to coordinate separate modalities on the same frame (i.e. pressing down on main_stick on the same frame as pressing button B).
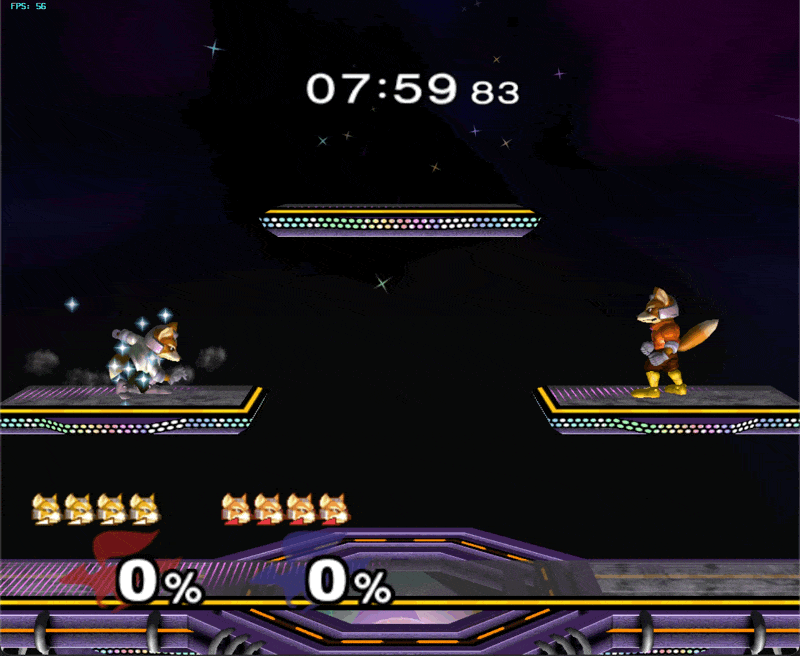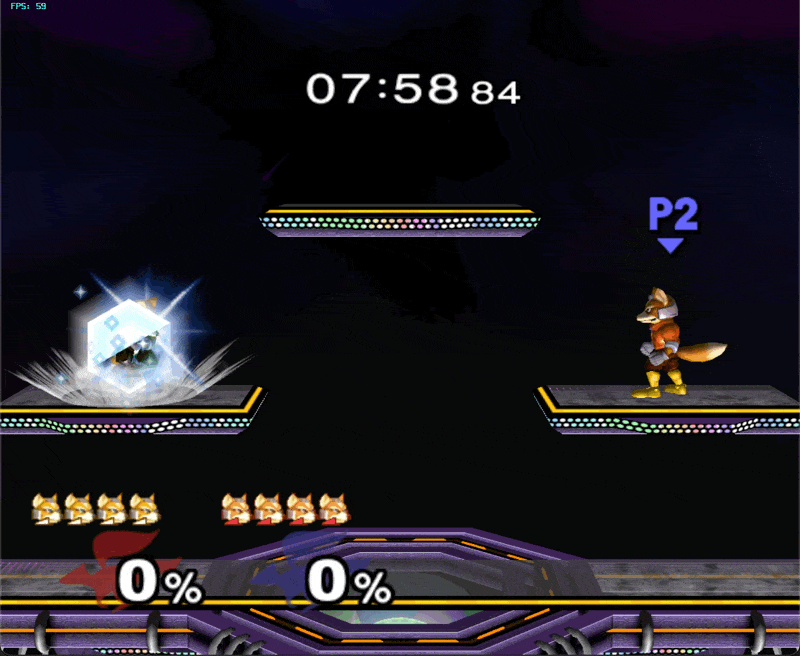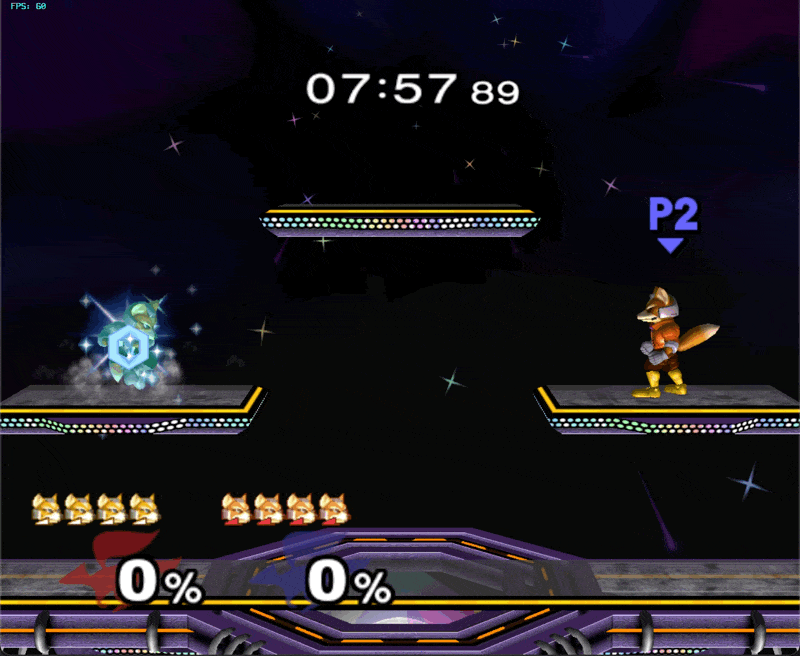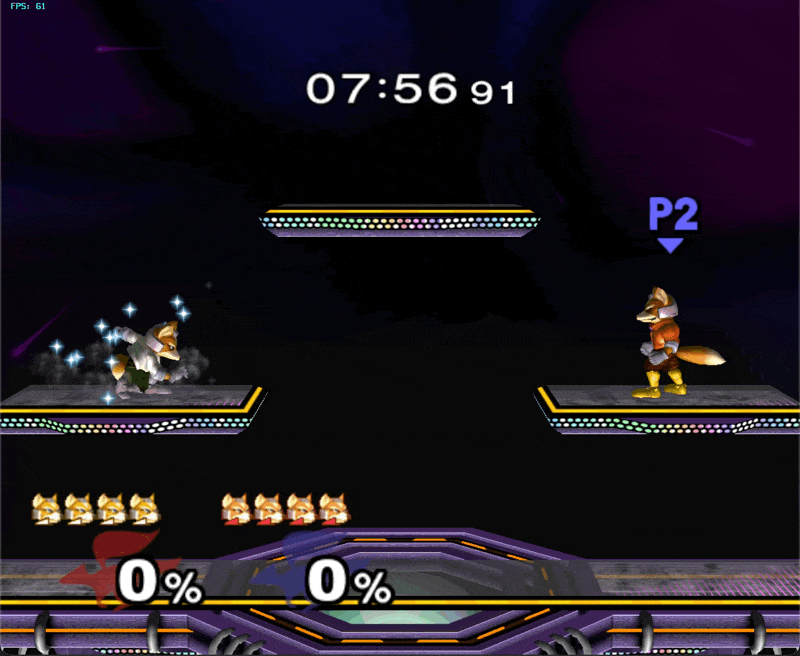
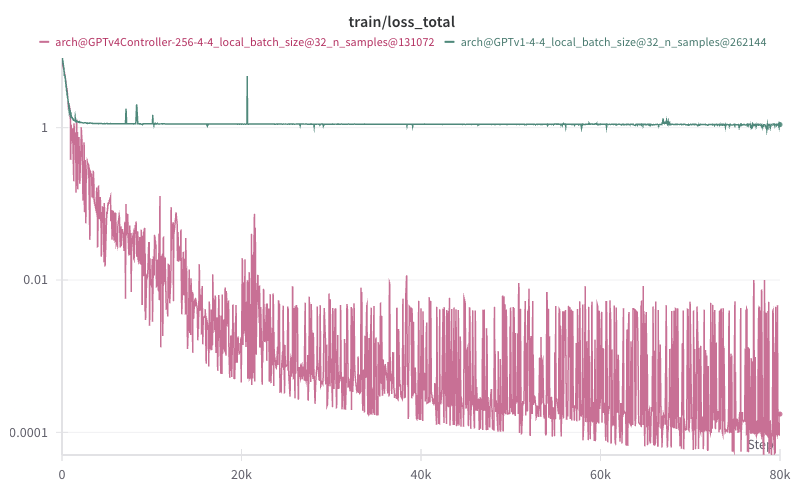
small model successfully overfitted on multishine and running in emulator
Categorical variables like action have hundreds of classes. Most are rarely used (power law), so in my model, I down projected with a learned embedding shared between players before concatenating numeric inputs. This saved parameters by avoiding a fat matmul on a sparse input vector. Combined with coarse discretization on the agent’s controller inputs from previous frames, this decision saved over 1M parameters in the input layer.
Here’s the architecture along the data dimension for a single frame:
 model architecture—batch and seq_len dimensions not depicted
model architecture—batch and seq_len dimensions not depicted
To aid in all of the above, I designed my code base such that I could easily register new preprocessing functions and models, and it would automatically adjust input & target layer shapes according to the config. This let me freely experiment with feature engineering, embedding sizes, sequence lengths, target discretizations, and architectures until I found a combination that performed well.
Closed loop evaluation
The second most important thing that I did was to create a closed loop evaluation harness.
Often in robotics, open loop performance (validation loss) does not track with actual performance in the test environment.8 A Monte Carlo estimate of model performance against a baseline opponent in closed loop is our best signal. This environment will also be necessary at a later stage of the project for online reinforcement learning, so I took pains to build something hackable yet performant.
I used a multiprocessing.Pool of CPU workers to run dozens of instances of Dolphin emulator. I batched inputs, performed a forward pass on the latest model checkpoint, sampled from the model’s predictions, and flushed button and analog stick presses to the virtual controllers. To avoid the overhead of serializing tensors for IPC, I wrote to input and output buffers in pinned and shared memory for non-blocking transfer to GPU. Here’s a diagram of what that looks like:

With a 7M model running on RTX 3090 and 32 CPU workers, the timings for one emulator step look like this:
| Eval step | |
|---|---|
console.step() |
4-5 ms |
preprocessing |
1.5-3 ms |
update context |
0.3 ms |
buffer writein |
0.15 ms |
batched model.forward() |
5-7 ms |
buffer writeback |
0.1 ms |
postprocessing |
0.4 ms |
send controller inputs |
0.15 ms |
total |
12-16ms |
There are more optimizations to be made. We should overlap the context update with worker preprocessing, and we can use KV caching, model distillation, and multi-token prediction to work around the 5-7ms inference budget—but that’s for another day.
In hindsight, I would have thought harder to design clever metrics earlier on so that runs could still be compared when improvements started to fall within the eval noise for “stock win rate.” Train and validation losses are no longer comparable once you’re fiddling with the number of target classes, and aren’t always correlated with closed loop performance anyways. Besides match win rate, stocks won/lost, and damage dealt/taken normalized by number of episodes, I wish I had also normalized by number of frames and tracked stats like average damage at kill, average time per kill, average combo length, or openings per kill from the start. These require coming up with heuristics but would’ve provide more granular dimensions to measure progress along.
Experiments
Great! Now we have all the ingredients needed to train a model on human replays. Below, I list both positive and negative results from experiments I tried (roughly in order of increasing surprise), and some speculative explanations for them.
Making the model wider and shallower improved both performance and latency. Increasing sequence length from 128 to 256 frames had dramatic improvement, but gains were diminished going to 384.
Increasing batch size from 256 to 512 resulted in near linear training speedups.
- It seems we were under the critical batch size.
- Going to 1024 made the model generalize much worse—there’s some noise from smaller batch sizes that seem to help regularize learning.
Feeding controller inputs from previous frames and using autoregressive MLP output heads instead of independent, shallow linear heads were key to the model’s expressivity and accuracy in closed loop.
- I thought the transformer blocks in the model trunk would learn to write into separate dimensions of the latent space for the shallow output heads to read from, but it seems the nonlinearities were necessary.
- Same for explicitly adding previous controller presses instead of inferring from changes in game state—at small scale, inductive biases are important!
Relative position encodings (Huang et al., 2018) achieved the same validation loss in half the number of steps as trained absolute position encodings, but were about 37% slower in wall clock time per step.
- The slowdown is mostly from not being able to call FlashAttention CUDA kernels when using a modified self-attention with relative positional encodings.
- The improvement makes sense since controller input timings should mostly be determined very locally by how many frames apart they are from previous game state and controller presses, instead of forcing the model to learn to subtract arbitrary absolute embeddings.
- I did not try static sinusoidal encodings (but should).
Fourier positional embeddings I assumed would provide the model with high- and low-frequency features for better understanding character x, y positions, but this did not seem to help.
- Other input features (
action_frame,hitlag_left,invulnerability_left,ECBx, y coordinates9) were also too noisy. - All stages are at fixed absolute positions, so the model is able to memorize ledge locations and infer whether it’s falling based on its action state.
- I did not (but should) try calculating the diff of character x, y positions between frames as an input feature.
Controller discretization had mixed results. The left three below were roughly tied in closed loop performance.
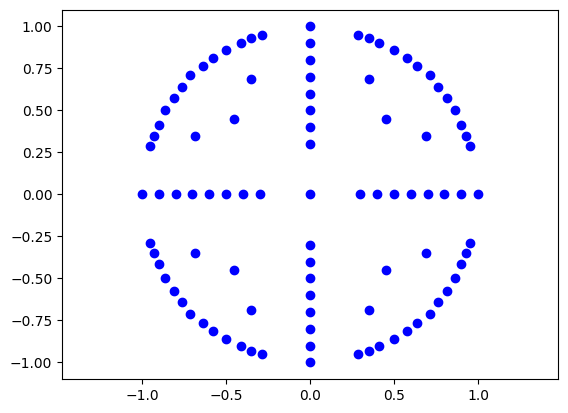
- I thought that all else equal, more target discretization would be better, but in fact, the rightmost did worst by far.
- Maybe due to player behavior and discretization in the game engine, the effective number of angles actually used on the controller are relatively few. It’s possible I didn’t train long enough or have enough data, and coarser discretization has higher accuracy & less divergence in this regime.
However, due to discretizing analog target features, validation loss often tracked well with closed loop evaluation metrics, something rare to see in control tasks. 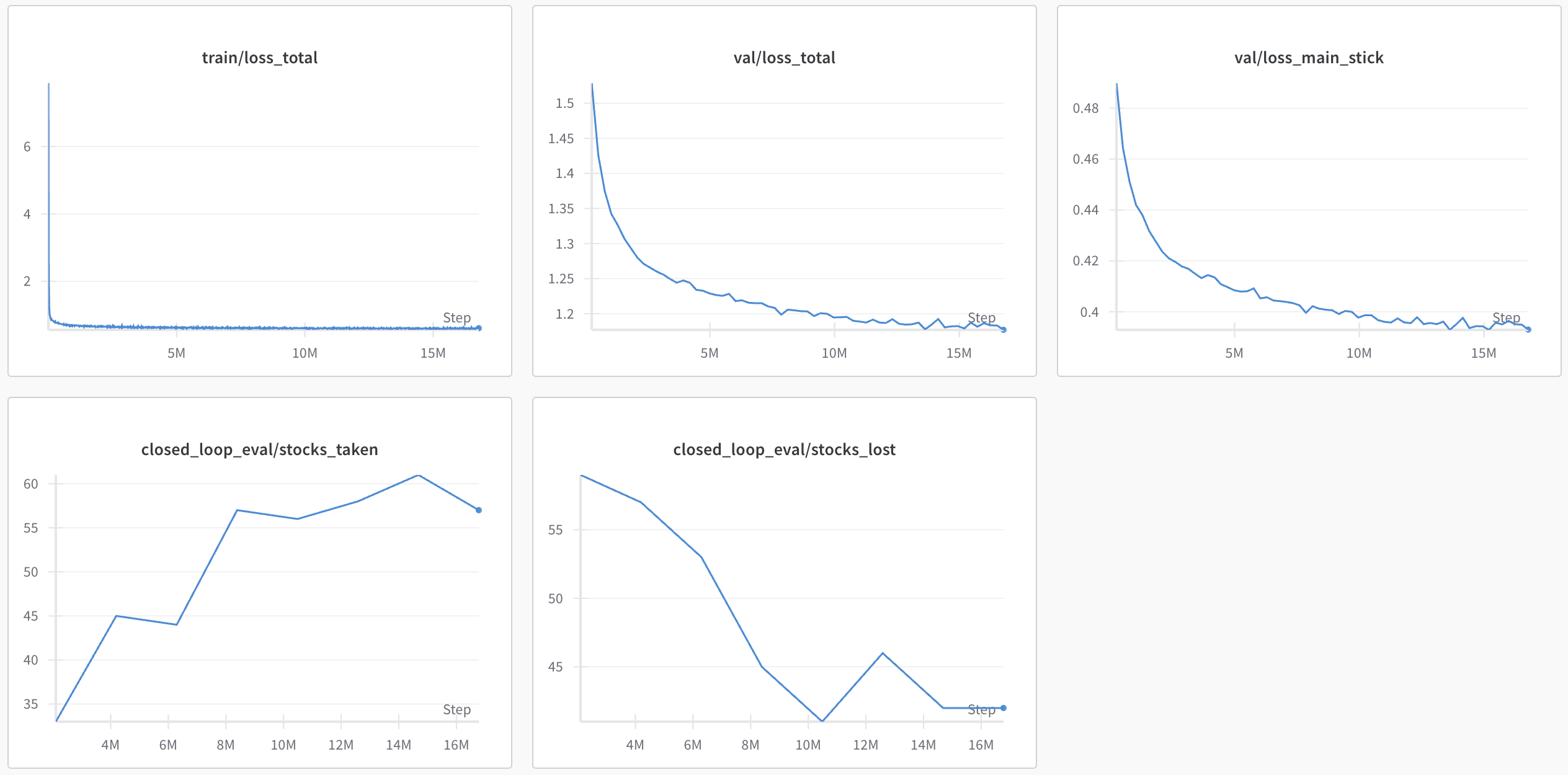
- Melee can be unforgiving to errant inputs, so in a large human dataset, there are lots of examples for recovering from bad trajectories, which is important for behavior cloning.
- I did not try predicting raw recorded button presses (but should).
A custom idea that did not work: I tried label smoothing by distributing the probability mass of a 2D Gaussian around the ground truth x, y to nearby reference points, like so:
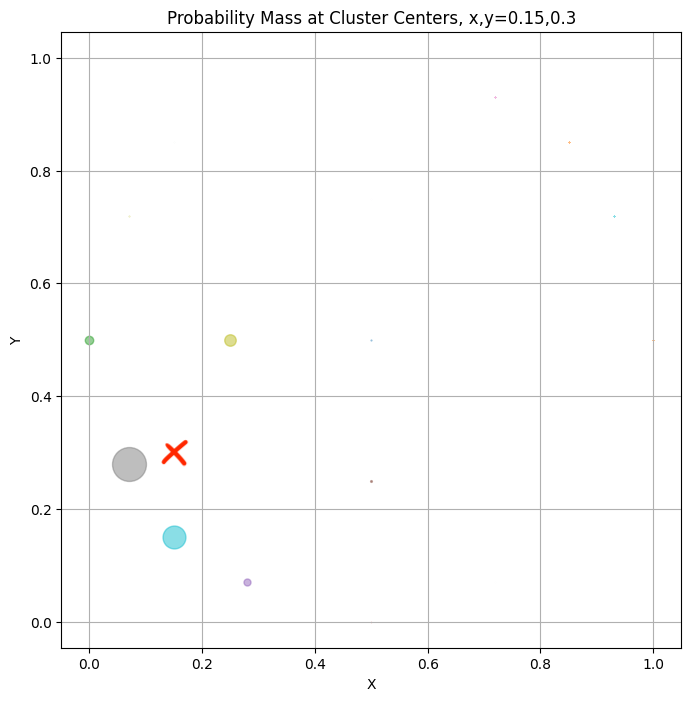
- I was surprised because this idea is similar to a 2D version of Farebrother et al., 2024 that uses Gaussian histogram loss. A related intuition I’ve had about why knowledge distillation works well is that it provides “dark knowledge” in the form of soft labels.
- Maybe this injected more noise to the model’s logits than was necessary. Given how unforgiving & path dependent the game environment’s dynamics are, errant button presses can be deadly.
Learnings
- Investment in tooling almost always pays for itself
- I spent nearly 40 hours at the beginning of the project getting the emulator to work (building from source on older version of
glibc) and ensuring it reproduced inputs. Huge thanks to Vlad for help on this. - Once my training code was up, my workflow became: launch job, watch Weights & Biases,
rsyncreplays to laptop, and analyze in Slippi Lab. - Logging closed loop eval metrics in W&B meant I usually didn’t even need to look at replays to know if a run was performing particularly well or poorly.
- I spent nearly 40 hours at the beginning of the project getting the emulator to work (building from source on older version of
- Premature optimizations sneak up on you
- I wanted to use serializable configs to define everything so that experiments would be deterministic and reproducible from W&B.
- But, this led to needing to pass config objects across APIs everywhere—I understand now why research scientists like to use global namespaces like
absl.flags. - I never ended up needing to tune certain hyperparameters.
- But, this led to needing to pass config objects across APIs everywhere—I understand now why research scientists like to use global namespaces like
- I liked having registries for data preprocessing functions and model architectures in code, as they made launching from CLI easier.
- I wanted to use serializable configs to define everything so that experiments would be deterministic and reproducible from W&B.
- It’s hard to exercise the restraint to avoid changing more than 1 thing per experiment.
- A dev log is great, but once I was in the research portion of a project, writing things down as if presenting findings to an advisor with less context often helped clarify my thoughts enough to get unstuck.
- tensordict is an underrated library. Very helpful for multimodal and RL settings, of which this was both. It helps to avoid tedious dictionary comprehensions when slicing input & output tensors during data preprocessing, training, and eval, and
.to()is automatically asynchronous under the hood.
Pitfalls
Here were some silly issues that I ran into at various points.
- Be careful with the dimensions you pass to
torch.nn.CrossEntropyLoss. I had nonsensical loss for a while because my dimensions were(batch, seq_len, C)instead of(batch, C, seq_len)or(batch * seq_len, C). - Detach output heads when feeding them to each other autoregressively. You usually don’t want to take different numbers of gradient steps on the same batch for different heads in non-adversarial settings.
- In closed loop, be careful about padding and selecting model predictions from the correct index in the context window—this is usually
min(curr_episode_frame, block_size). But, during training, I sampled frames at an offset—(1, episode_len - seq_len)—due to using controller inputs from the previous frame as an input feature. This means you should accordingly discard 1 frame at test time! - The Dolphin emulator can be finicky to configure—by default, it is set up for online play and incorporates a 2 frame delay, which must be set to 0 for local eval. If running multiple in parallel, it’s important to point everything to temp directories so that configs and replay writing streams don’t mutually interfere.
Footage
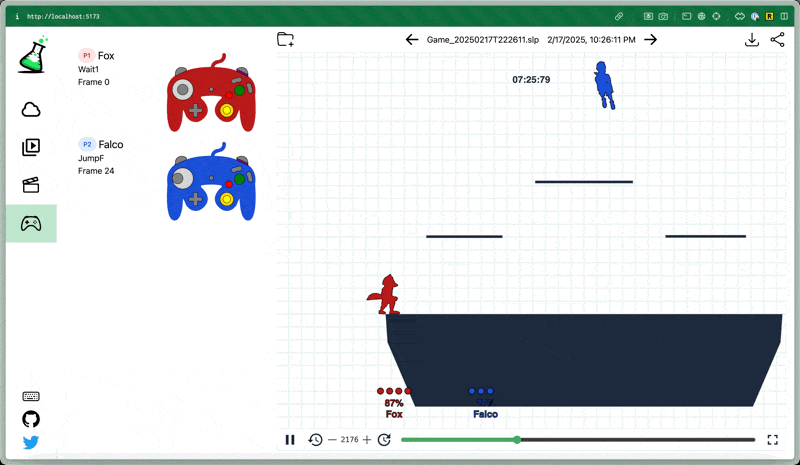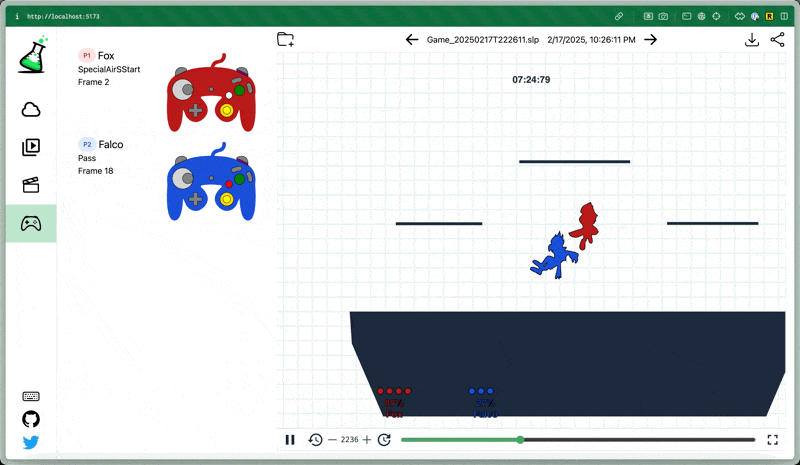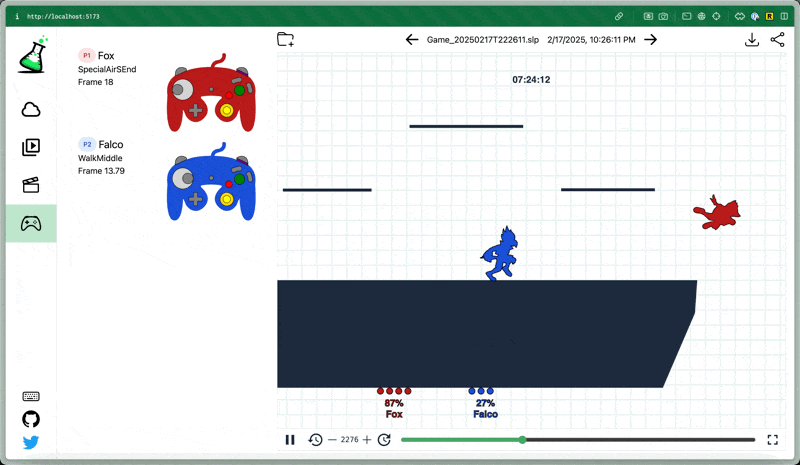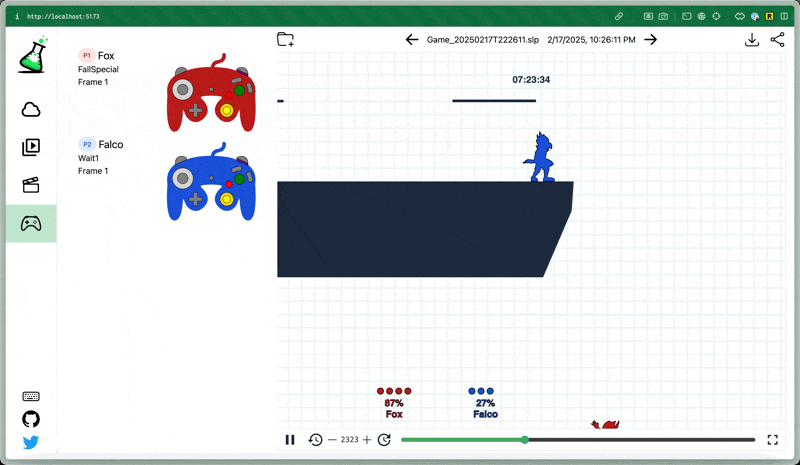
Below are clips of earlier and current versions of the model playing the level 9 CPU and some interesting things I noticed.
Remember that the model can’t explicitly see anything about the stage at all, including platforms and projectiles.
Here’s an example showing the difference in behavior between an earlier and later model. The stick movement is erratic in the first, and relatively humanlike in the second.
The model practices moonwalking between stocks. 
It can pivot f-smash.
When I trained it on Cody, it’s a menace on the ledge. It even goes out for Armada shines but totally whiffs. In general, the model is full jumping and missing wavedashes all the time from pressing X for too long (because it’s bad at counting frames).
Sometimes, it will kill itself trying to recover and imagining Randall is there.
The level 9 CPU it’s playing against has superhuman DI and frequently gets out of moves (up air) that normally combo or kill, which I think gives a pessimistic demo of the model’s ability to combo human players.
Earlier on, the model frequently mis-input side-B as Fox, which often results in a self-destruct. However, you can save yourself by pressing B exactly on frames 20-24 to shorten the move and stay on stage. You can see the model attempting (but failing) to do that here.
What’s next
In my next blog post, I plan to experiment with 10x more data, bigger models, inference optimizations, offline RL, dealing with network latency with multi-token prediction, and playing against humans—stay tuned.
If you want to collaborate or know a pro player willing to contribute data, please reach out by email or twitter. I’d also love to hear any thoughts and feedback in the comments!
Thank you for reading.
Acknowledgements
Countless friends gave me encouragement and feedback. I want to particularly thank Stephen Wu and Kate Yeh for their support, and Alex Reibman for reading an early draft.
Thank you to Eric Jang for his valuable advice on imitation learning and riffing with me on RL.
I’m grateful to Fizzi and Vlad Firoiu for paving the way with improvements to Slippi and Dolphin which made this project possible.
$2 in S3 egress, $0.6/hr for GPUs at latest Vast prices
 ↩︎
↩︎There’s a risk that players will use AI to cheat in online competitive ladder, which is why I’m not releasing weights just yet. I’ll work with the right folks to mitigate this. For the record, I don’t think AI will destroy competitive Melee. Nintendo has tried and failed for years, but the community is insanely strong and grassroots. I’m also optimistic that the net impact of releasing model weights will be positive from looking at chess, where engines have dramatically improved average skill level while the player base is at an all-time high.↩︎
At float32,
~100 cols * 4 bytes * ~10k frames/episode * 1M episodes = 4000GB↩︎As an example: the L/R shoulders control the shield as a function of
max(l_shoulder, r_shoulder). They are clamped to 0.0 for values under 0.3 and hide a digital button inside that registers as a separate input.↩︎Independently outputting probabilities for each button to fire on every frame results in a lack of “coordination”—button presses often need to occur in correlated groups, with tight timings across frames.↩︎
There are hundreds, if not thousands, of unique “entities,” many of which still have not been deciphered from the ROM. Among these, ordinary projectiles each have unique hit boxes, durations, and interactivity.↩︎
Ice Climbers are actually two characters in one, each with independent player state. After I got my baseline working, I actually spent over a full day trying to retrofit Nana into my data schema and codebase. This required reprocessing terabytes of replays and touched nearly all parts of my code because of broken assumptions. I eventually gave up and decided the AI would have to manage with only seeing Popo—sorry IC mains!↩︎
Data scarcity—you need a lot of expert demonstrations to get adequate coverage of all the different states the agent might visit in the environment.↩︎